本来这篇文章还有一个小标题,完整的大概是这样:“JIT优化——如何让解释型语言的执行效率超过编译型语言”。但是这太夸张了,已经算是标题党了,所以我把这个小标题砍掉了。
这还是一篇为上课分享而写的文章,所以照例先写一些废话。之前老师上课讲到解释型和编译型语言谁的效率更高的时候,给出了一个非常绝对的结论,肯定是编译型的语言效率最高,因为解释型的语言需要边解释边执行,造成的性能开销肯定更大,效率更差。
照理来说是这样的,而且统计数据也证实了这一点。有开发者根据 The Benchmarks Game 的测试数据制作了一份可视化图表,具体可见:编程语言效率可视化
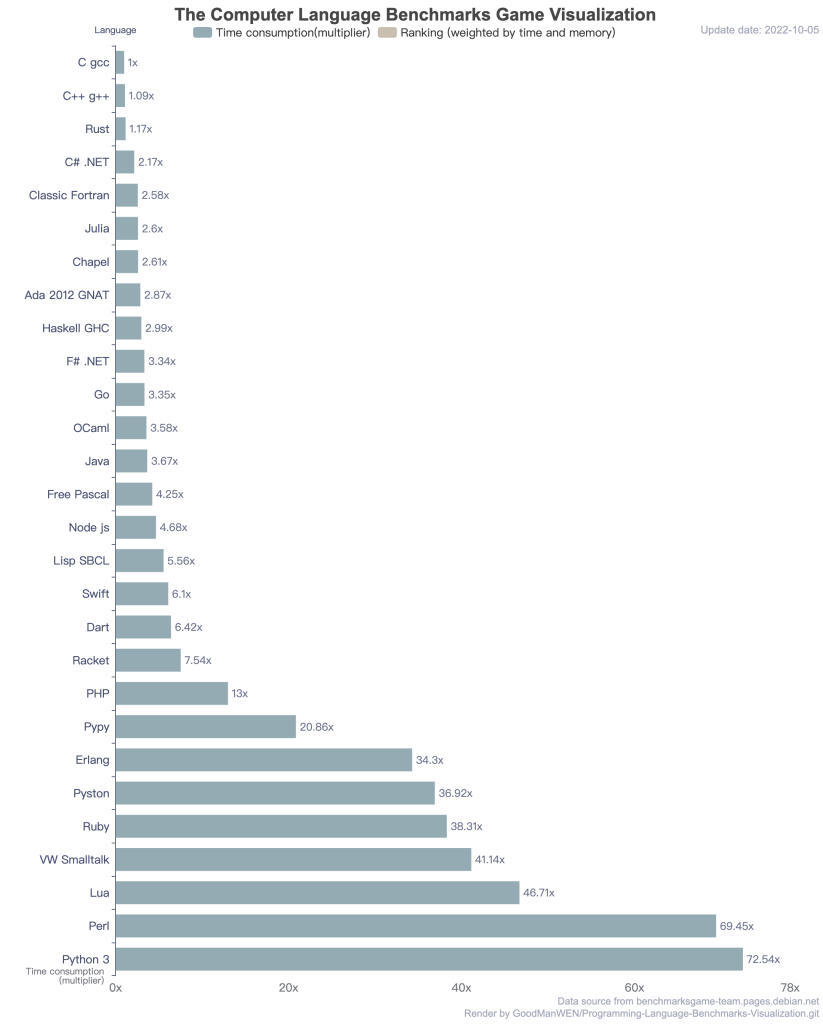
事实上从绝对性能上来看,Go,Java一类的解释型语言效率并不差,但肯定是没办法跟C相提并论的。
Sun在上个世纪就已经意识到了这个问题,当然也给出了一些解决方案,其中之一便是JIT。先不讲原理,看效果。
//C版本
#include <stdio.h>
#include <time.h>
int f(int n)
{
return (n<3)? 1 : f(n-1)+f(n-2);//如果是前两项,则输出1
}
int main(int argc, const char * argv[]) {
int n;
clock_t start, finish;
double Total_time;
n=45;
start = clock();
printf("%d\n",f(n));
finish = clock();
Total_time = (double)(finish - start) / CLOCKS_PER_SEC; //单位换算成秒
printf("%f seconds\n", Total_time);
return 0;
}//Java版本
public class Main {
public static int f(int n){
return (n<3)? 1 : f(n-1)+f(n-2);//如果是前两项,则输出1
}
public static void main(String[] args) {
int n;
long start, finish;
double Total_time;
n=45;
start = System.currentTimeMillis();
System.out.println(f(n));
finish = System.currentTimeMillis();
Total_time = (double)(finish - start) / 1000; //单位换算成秒
System.out.println(Total_time);
}
}# Python 版本
import time
def f(n):
if n < 3:
return 1
else:
return f(n - 1) + f(n - 2)
if __name__ == "__main__":
n = 45
start = time.time()
print(f(45))
end = time.time()
print(end - start)很简单,就是计算斐波那契数列的值,这里初始值取45,能看出性能的差距,耗费的时间也不会很长(Python除外)。
运行时间如下:
//C
1134903170
3.865728 seconds
Program ended with exit code: 0
//Java
1134903170
2.515
进程已结束,退出代码0
//Python
1134903170
207.55029606819153
进程已结束,退出代码0可以看到一个奇怪的现象,那就是Java运行耗时会比C更短。在代码结构完全相同的情况下,JVM一定在运行时帮我们做了很多工作。在这段代码中,功劳最大的便是JIT(其实是Java的内存管理)。
JIT即时编译器介绍
为了优化Java的性能 ,JVM在解释器之外引入了即时(Just In Time)编译器:当程序运行时,解释器首先发挥作用,代码可以直接执行。随着时间推移,即时编译器逐渐发挥作用,把越来越多的代码编译优化成本地代码,来获取更高的执行效率。解释器这时可以作为编译运行的降级手段,在一些不可靠的编译优化出现问题时,再切换回解释执行,保证程序可以正常运行。
即时编译器极大地提高了Java程序的运行速度,而且跟静态编译相比,即时编译器可以选择性地编译热点代码,省去了很多编译时间,也节省很多的空间。目前,即时编译器已经非常成熟了,在性能层面甚至可以和编译型语言相比。不过在这个领域,大家依然在不断探索如何结合不同的编译方式,使用更加智能的手段来提升程序的运行速度。
上面这段话又是我抄过来的。简而言之就是,JVM会将一些经常执行的代码段编译为机器码来执行,这部分代码的执行效率便可以与编译型语言相媲美。很显然,上述斐波那契数列递归计算部分一定被编译为机器码。
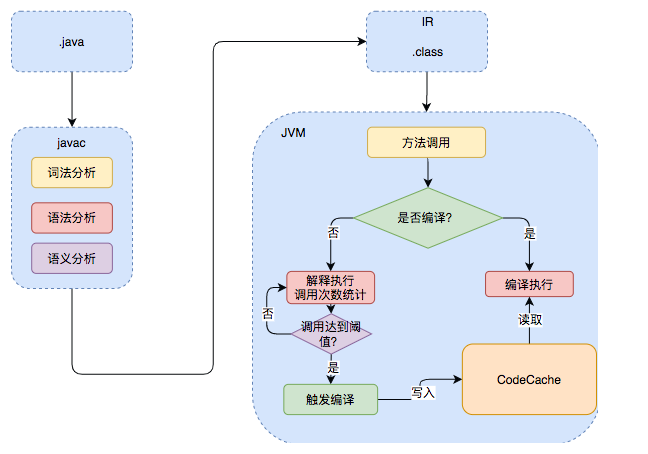
但这不足以解释为什么Java的执行效率会超过C。JVM一定还做了其他工作!
接下来我通过一个例子来说明JVM到底做了哪些工作,当然很不全面,例子也是我抄来的。
首先给出一段代码:
class Calculator {
Wrapper wrapper;
public void calculate() {
y = wrapper.get();
z = wrapper.get();
sum = y + z;
}
}
class Wrapper {
final int value;
final int get() {
return value;
}
}假设这段代码是Hot Spot,JVM并不会直接把这段代码编译为机器码,而是会对其进行优化。最终是把下面这段代码编译为机器码。
class Calculator {
Wrapper wrapper;
public void calculate() {
y = wrapper.value;
sum = y + y;
}
}
class Wrapper {
final int value;
final int get() {
return value;
}
}这些代码的优化都是遵循一些固定的方法的,一步一步进行优化。
- Inline Method(方法内联)
用b.value取代wrapper.get(), 不透过函数呼叫而直接存取wrapper.value来减少延迟。
class Calculator {
Wrapper wrapper;
public void calculate() {
y = wrapper.value;
z = wrapper.value;
sum = y + z;
}
}- 移除多余的载入
用z = y取代z = wrapper.value, 所以只存取区域变量而不是wrapper.value来减少延迟。
class Calculator {
Wrapper wrapper;
public void calculate() {
y = wrapper.value;
z = y;
sum = y + z;
}
}- Copy Propagation(复写传播)
用y = y取代z = y,没有必要再用一个变量z,因为z跟y会是相等的。
class Calculator {
Wrapper wrapper;
public void calculate() {
y = wrapper.value;
y = y;
sum = y + y;
}
}- 消除不用的源代码
y = y是不必要的,可以消灭掉。
class Calculator {
Wrapper wrapper;
public void calculate() {
y = wrapper.value;
sum = y + y;
}
}最终优化完成。
一些小提示,提示我上课的时候要讲什么:
JMH基准测试
