
碎碎念的废话
第一次接触到Docker大约是在半年前。当时出于数据采集需要,买了一块可以采集血氧,心率等生理指标的手表,与手表搭配的是一台网关,手表与网关相连接,我们直接从网关拿数据。整个流程大概是这样的:

之前同样有接触到过从传感器拿数据的案例,是从传感器的串口中直接取出二进制数据。当时这个可折腾了,我花了一个多星期,终于把取数据,解析数据一套工作完成了。过程非常复杂,还用到了额外的dll动态链接库,而且只能在Windows系统上操作,非常不舒服。
从网关拿数据,我以为还会像以前那么麻烦。实际上发过来的使用文档非常短,与之配套的还有一个tar格式的文件,这个文件就是我接触到的第一个Docker镜像(一开始我不懂,还给解压缩出来看看)。在这之前我是没有接触过Docker的,按照文档的提示,我花了大约半个小时便从网关成功拿到数据,很快,很方便。
不过当时我还没有研究过Docker的具体细节,只是将它当作一个盒子来用。由于经常会看到Docker相关的内容,觉得这个东西还是相当有用的,想找个时间好好看看这个技术。恰好我的一门课有一个不错的讨论作业,超多主题任选,不少主题都能跟Docker找到一些联系。我就借此机会,好好谈一谈Docker的一些技术细节(可能会有大量的错误与表述不准确)。
本篇文章同样作为一个作业上交,所以按要求列出所选的三个主题与对应的内容:
- 容器技术:Docker
- 虚拟机隔离:Docker容器隔离与虚拟机隔离
- Copy-on-Write技术:Docker的镜像分层实现
理论性质的内容不是很多,而且我在这方面并没有太多实践,所以大多数内容会谈到自己的个人理解和一些应用计划。
容器技术:Docker
我对Docker的误解
一开始我对“虚拟化”这个概念理解十分不清晰,一谈到“虚拟”两个字,我就想到了虚拟机,联想到我在Mac上跑Windows虚拟机时糟糕的体验,我对“虚拟化”的第一印象就是,浪费资源(因为我需要获得某个特定应用提供的服务,不得不跑一个完整的Windows系统,本身Windows系统占用的资源比我需要的应用多得多)和效率低(肯定没有在物理机上效率高),这差不多也是我对Docker的第一印象。
后来我发现,很多常用的应用都提供Docker部署方式,Nginx,Redis之类的,部署起来既迅速,占用的资源又低,而且好像也没有像虚拟机一样,启动一个完整的系统。这个时候我开始慢慢意识到,Docker跟我之前认识的虚拟机(单指VMWare一类的虚拟机,而不是JVM这样的,虽然这都是虚拟机)有本质上的不同。
容器、虚拟机
Docker的图标可以让我们直观的理解容器是什么,一个大鲸鱼,装着一堆集装箱,各个集装箱都是独立的空间,互不干扰,共同共享一个大的运载环境。

Docker的官方给出了容器与虚拟机的不同结构图,这里我直接引用,通过与虚拟机的对比,更好的解释容器的概念。
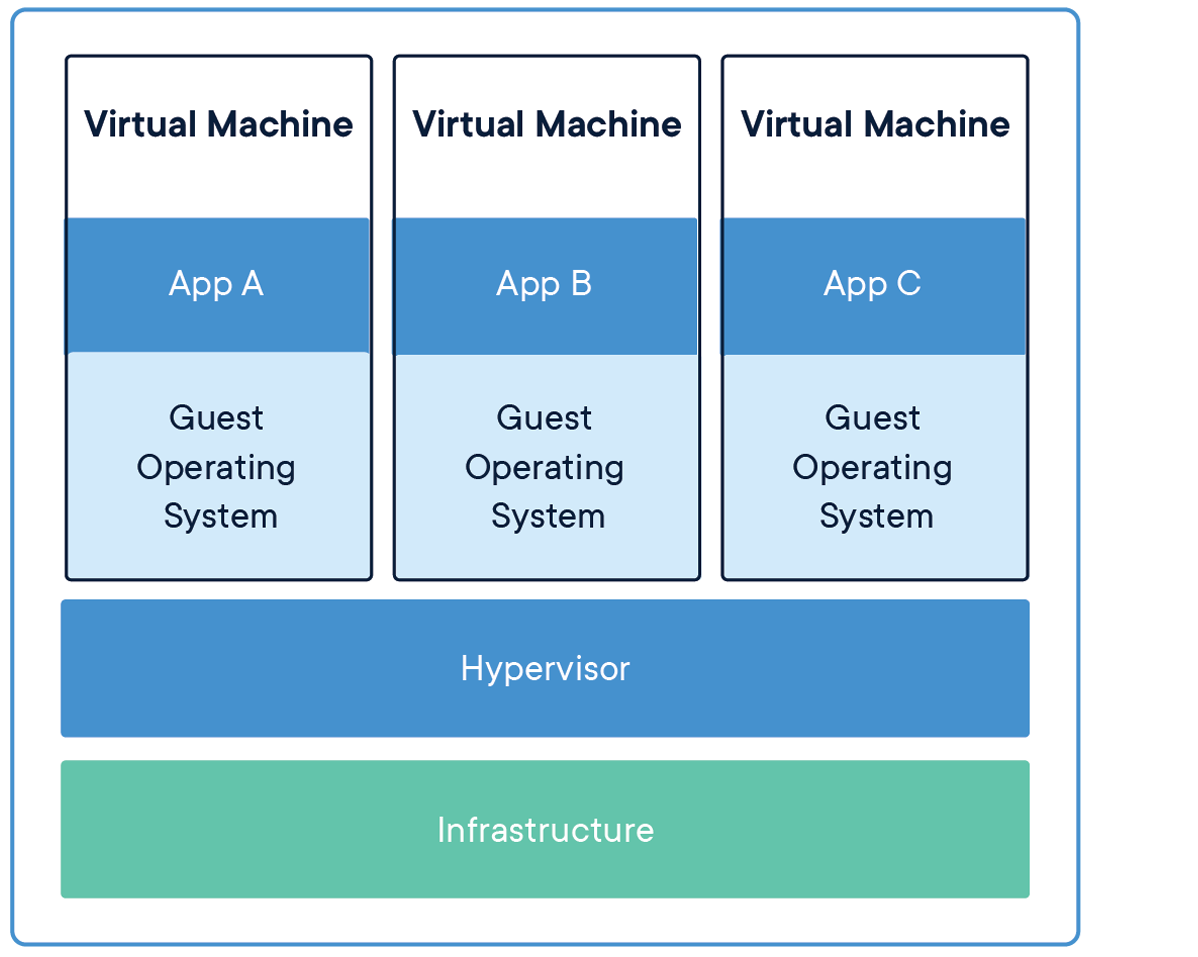
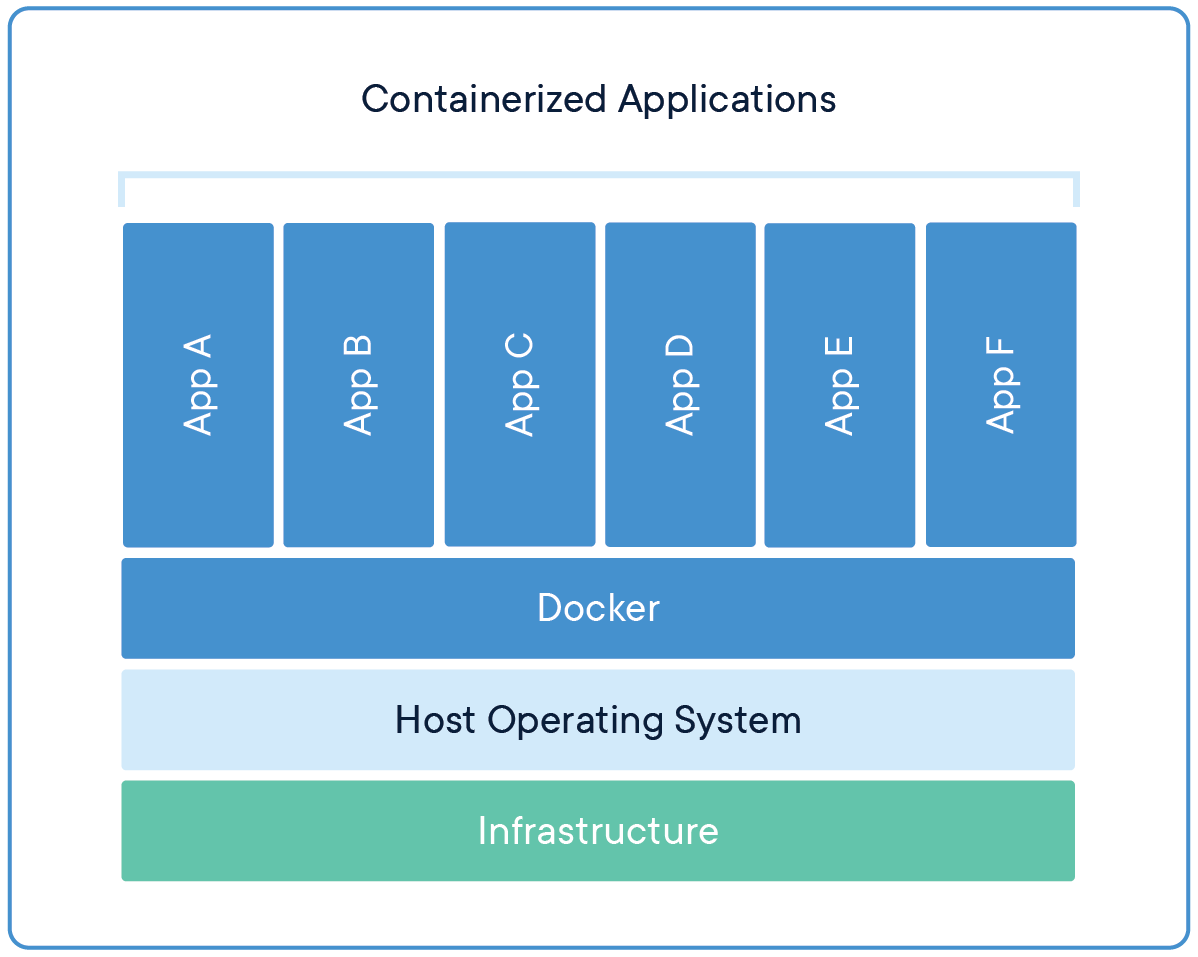
可以看到,容器内的应用并不运行在监视器与虚拟操作系统之上,而是运行在宿主操作系统之上的,所以这就大大降低了这两层带来的性能损耗,带来与物理机相似的性能表现。由于不需要运行大量的不必要组件,Docker的容器的内存占用也是非常小的。
下面给出一个在Mac上运行的Docker内存占用情况示例,内存的占用真的非常棒!一个Redis服务启动居然只占用了不到3M的内存,跟虚拟机比起来真的好太多了。
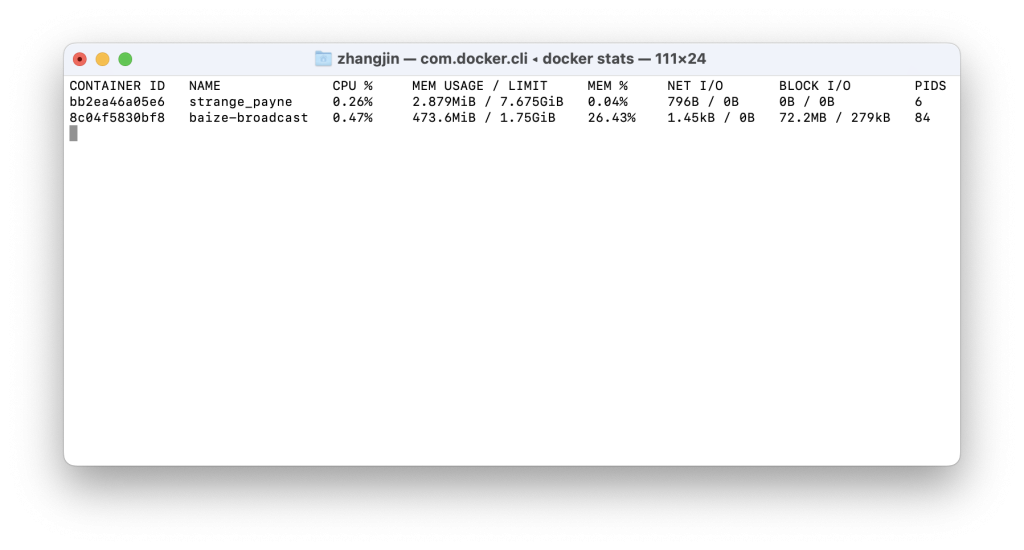
概念性的东西不说太多,本来还想讲讲镜像的分层的,不过内容比较多,以后再讲。接下来还是讲讲我自己的经历。
在Windows平台使用Docker
上面我有讲到,我之前有过连接传感器的经历,那套传感器只能在Windows上连接使用,为了方便整合,我决定把Docker也搬到Windows平台。
这个时候就出现了一些问题,在安装Docker时,我还需要启动Hyper-V。
其实当时我也没有多想,就启动呗,反正不是家庭版系统。不过我还是发现了一些问题,比如初次启动Docker非常的慢,远不及Mac来的快,我简单将其理解为机械硬盘和固态硬盘的差距。现在回过头看在Windows系统部署Docker其实是非常不明智的。
因为Docker本质上是一个Linux容器,它需要借助Linux内核来完成资源的调用,而Windows却不属于Unix系的OS,这就需要借助Hyper-V先构建出Linux环境,再在Linux环境中运行Docker,本质上还是跑了一个虚拟机。
在另一门分布式数据库的课上老师就曾经提到,Windows并不适合用来部署Docker,当时我没有在意,毕竟在我看来Windows不适合干很多事情,不适合用Docker那也是正常的。现在我才理解其中的原因。
对Docker应用的一部分计划
既然我决定花时间研究容器,代表着我有一些应用场景需要,所以来简单谈一谈我对Docker的一些应用计划吧。受限于时间与精力,这些都是设想,还没来得及完全的实践,部分已经实践过的场景也不是很理想。
我现在在做的一个小项目业务逻辑比较复杂,由于技术有限,精力有限,肯定没办法把项目优化的很好的,这么一个复杂的逻辑就容易出问题。
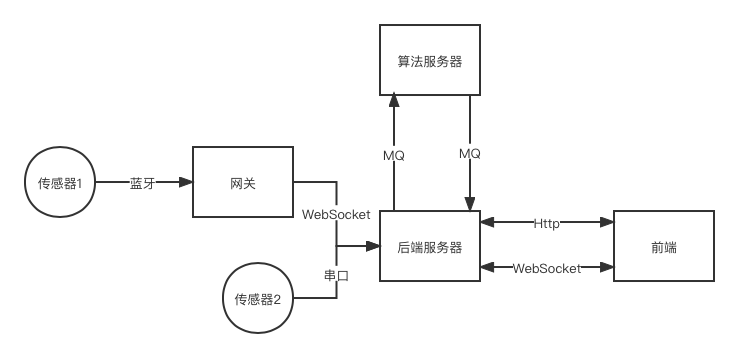
上述流程图中,最容易出问题的一定是后端,但应用部署的后端太容易挂掉了。所以在搭建这个后端时,我用了Spring Cloud微服务,将各个功能模块分开部署。
提到部署多个功能模块,这个就是Docker擅长的东西,而且环境比较好整合,部署也方便。
这其中需要用的一些应用,比如说RabbitMQ,Nginx等一定会用Docker容器进行替代。接下来是自己写的一些业务,例如数据处理算法,一般的后端业务(对数据库的操作),传感器的连接,这些业务会被分成一个一个的模块,然后分别打包为Docker的镜像,进行部署。这样就算其中的一个模块出问题了,解决起来也是相对容易的。
这就是目前我对Docker应用的一些初步设想,还很不成熟,实际实现过程中一定会做一些调整的。
虚拟机隔离:Docker容器隔离与虚拟机隔离
前面我们讲到容器与虚拟机的一些差别,只谈到了Docker的一些优点,没有谈到缺点,实际上“隔离”正是Docker的一个缺点。这个时候可能会有疑问,Docker的各个容器都是独立运行的,互不干扰,为什么“隔离”会成为缺点?
隔离不是缺点,缺点是“隔离的程度不够高”。
在这个主题,会通过比较虚拟机隔离与容器隔离,来说明两种隔离方式的优劣。所有的比较均基于个人理解,不详细,可能会有错误。
虚拟机隔离引入
在创建虚拟机时,我们会选定分配给虚拟机的资源数量,包括CPU核心数,内存,硬盘等等,这些都可以认为是给虚拟机指定的一个相对独立的运行环境。虚拟机中运行一个完整的OS,有着独立的内核,独立的资源调度方式,尽可能的与宿主系统独立开。
这个独立能做到什么程度呢,只要CPU支持虚拟化,甚至可以在32位的操作系统上运行64位的虚拟机。当然架构是肯定变不了的,ARM架构不可能给你虚拟化成x86架构。
容器隔离引入
讲到容器隔离,我们直接引入一个例子讲解。
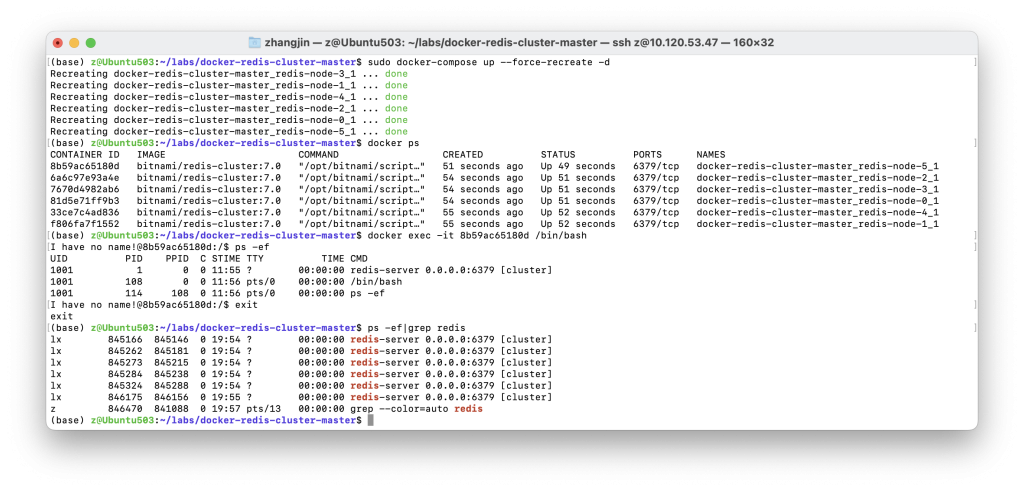
首先我们通过Docker Compose启动一个Redis集群,然后我们任选一个Docker容器,进入容器内部,查看容器内部的进程PID。之后我们退回到宿主机环境,查看Redis容器在宿主机的进程。
观察输出我们可以发现,容器内的进程与宿主机的进程并不统一。说明容器还算是一个相对独立的环境。但启动一个Docker容器,相当于是在宿主机中新开了一个进程,容器的对资源的调度操作其实是要遵循系统对进程的调度的,这样隔离性就大大的降低,。
举个例子,当某个Redis容器在处理高并发需求时,可能会占用大量的IO资源,此时如果其他的容器也恰好需要处理类似的需求,不同的容器之间就会出现抢夺资源的现象,这显然不是一个彼此独立的环境应该出现的问题,虽然下面要讲到的Cgroups可以解决这个问题,但这个问题在早期的虚拟化容器中是存在的。
虚拟机:对硬件的虚拟化
CPU虚拟化(Linux以及x86为例)
x86架构的一大特点就是特权模式,可以让CPU工作在RING 0至RING 3状态,三个状态的权限依次递减。Linux的内核就工作在RING 0状态下,用户程序则工作在RING 3。虚拟机肯定是不能工作在RING 0状态的,这样会与宿主系统的操作冲突,二者必然有一个会崩溃掉。
一个系统运行在某个CPU上,实际上就是在不断交换CPU寄存器的值。模拟一个虚拟的CPU,可以被看作模拟CPU的寄存器。我们只要给出CPU寄存器的数据结构,当虚拟系统的指令涉及到RING 0指令时,Hypervisor会拦截该指令,并修改数据结构中的值,让虚拟操作系统误认为自己运行在RING 0指令下即可。
除此以外,还有内存虚拟化,I/O虚拟化等,限于篇幅,在这里不在赘述。
简单谈谈我的理解。虚拟机的隔离是基于一种模拟硬件环境的隔离,隔离程度非常高。说的通俗一点,在现实中,我们的系统出现了故障,重装系统几乎成为了一种万能的方法,因为系统故障不会影响我们的硬件环境,对于虚拟环境,这也同样适用(某些时候,计算机病毒可能跳出虚拟机感染物理机,这是非常少见的)。
容器隔离:软件层面的隔离
在上述的例子中,我们看到容器里的进程其实是有独立的PID的,但容器并不像虚拟机那样有一个完整的虚拟化环境,而是可以被看作系统的一个特殊的进程。那容器是如何实现隔离的?
一个容器要想与其他容器互不干扰需要能够做到:
- 文件系统需要是被隔离的
- 网络也是需要被隔离的
- 进程间的通信也要被隔离
- 针对权限,用户和用户组也需要隔离
- 进程内的PID也需要与宿主机中的PID进行隔离
- 容器也要有自己的主机名
Linux的Namespace和Cgroups恰好能做到这些。NameSpace可以实现资源的隔离,Cgroups则限制容器对资源的使用。Docker正是通过这两种机制实现了进程层面的隔离。
基于这种系统机制的隔离,我将其看作软件层面的隔离。
二者比较
这里用一些直观的语言总结一下二者在隔离性上的区别。假如你是一个黑客,想要透过虚拟机去攻击物理机,首先你必须攻破虚拟机的内核,然后再向下找到Hypervisor的漏洞,通过其漏洞攻击物理机的内核,层层嵌套下,相当困难。而Docker的漏洞就好找到了,你甚至在网上就可以找到案例,可以移步:初识Docker逃逸漏洞。
Copy-on-Write技术:Docker的镜像分层实现
背景知识提要
这个部分就比较复杂了,需要讲的部分有点多,许多东西也是我第一次接触到。
在这个部分需要先简单介绍一下Linux中的fork()和exec()操作,然后引入我们的主题:“COW技术”,讲解Linux为何引入这个技术。
在上文中,我并没有介绍Docker镜像的结构,这个内容会放在这个部分一起说明,由此我们再讲讲Docker是如何使用写时复制技术的。
Linux中的fork()和exec()
首先明确,我这里讲的是Linux进程层面的东西,这两个函数都是与进程有关的。
Linux中的进程PCB中通常会包含三部分数据(仅仅是包含,还有很多其他的),所谓的“代码段”,“堆栈段”和“数据段”,理解JVM内存模型的人应该很容易理解这部分内容。在这其中,代码段其实是可以共享的,例如我使用VS Code打开了两个项目,实际上这两个进程会共享一部分VS Code程序的代码段,以达到节约内存的目的。
在Unix中,fork()和exec()分别用于进程的创建和修改。fork()会创建一个新进程,该进程是当前运行进程的一个基本一样的拷贝,而exec()则会让新的进程去替代当前进程。
很多时候,这两个命令是同一时间执行的,也就是说,当一个进程执行fork()后,会立刻执行exec(),用新的进程去代替当前运行进程。这个时候就会有一个问题,前面提到,fork()会创建一个与当前进程几乎完全一样的拷贝,而调用fork()会导致这些拷贝工作完全无用,反而是要对已拷贝的部分进行整页的重写。
Copy-on-Write——一个聪明的解决方案
其实这个东西非常简单。当fork()命令执行后,系统会立即开始复制当前进程的数据给新进程。而写时复制机制则将这个过程推迟到了子进程第一次往共享区写数据前。也就是说,一个新进程如果没有往共享区写数据,则会与当前进程共享相同的物理内存页。如果此时调用fork(),完全不会浪费资源在拷贝与重写上。由于大多数进程都不会涉及到写数据,所以该技术还节约了大量的物理内存空间。
Docker镜像分层与Copy-on-Write
介绍写时复制,其实是为了介绍Docker的镜像分层机制。这里我们先讲解一下Docker镜像到底是什么样的。在之前我们示例中,有进入容器内部看Redis集群的状况的相关命令。其实一个容器内部几乎可以执行任何Linux命令,甚至可以apt-get。这是因为几乎所有的Docker镜像都是在base镜像之上构建的(在这之前得先明白,Docker的镜像是有层次的)。那么base镜像到底是什么?你可以理解为众多的Linux发行版,而且镜像大多数是以MB计算的,因为这些镜像都没有内核,运行时使用宿主机的内核。

那么Docker镜像为什么要分层呢?当然是为了共享。不同的镜像可以共享一层或多层的内容,这样就会大大节省内存空间。例如我开设了一个网站,网站的有一些主要的业务模块,例如BBS和Blog,分别使用了PhpWind和WordPress镜像。而这两个镜像唯一的不同可能就是两个应用程序,其他的部分都一样,都使用了Nginx,用了MySQL,当然,都是PHP写的。这个时候我们两个镜像的大多数层的内容都可以共用。
说到这儿,再回过头来看,两个进程共享同一个段物理内存,这是不是跟Docker很像呢?
事实上,Docker的镜像层都是只读的,当一个容器需要修改某个数据时,Docker会依次从镜像层寻找文件,再将其复制到容器层当中进行修改。这样就可以保证及时共享一层或多层镜像,容器的隔离性也不会遭到破坏,这就是CoW机制在Docker中的应用。非常巧妙!

End
实际上在写这篇文章之前,我对Docker的理解可以说是非常的肤浅,所以导致这篇文章应该会漏洞百出。但这个过程中,我对Docker的理解有了很大的进步,相较于完成一篇文章,我觉得这才是我最大的收获。
最后希望我的作业能有个好成绩,真的好认真的写。
最后放一张Docker架构图:


确实,咱对docker一开始也是有浪费一部分性能的误解()