这学期上了好久的网课,导致我的《计算机组成原理》这门课一直没办法做实验,全是理论课,有一些东西就不是很好理解。
我在唯二的一节实验课上,简单的接触到了汇编语言,由于跟我学的高级语言差距太大,一时间也没办法接受。不过在那之后,我就再也没有上过实验课。
言归正传,在这篇文章,我会用Java语言来讲一讲Cache的一些工作原理,让大家能直观的体会到Cache的作用。
当然,这个程序不会太复杂,只有两个For循环语句和两个二维数组。先看代码,后讲原理。
package edu.njucm;
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.SingleShotTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Measurement(batchSize = 1000,iterations = 10)
@Warmup(batchSize = 1000,iterations = 5)
@State(Scope.Thread)
public class Cache {
int N=1000;
@Benchmark
public void Test1(){
int T1[][]=new int[N][N];
for (int i=0;i<N;i++)
for (int j=0;j<N;j++)
T1[i][j]=1;
}
@Benchmark
public void Test2(){
int T2[][]=new int[N][N];
for (int i=0;i<N;i++)
for (int j=0;j<N;j++)
T2[j][i]=1;
}
}
这个程序的目的很简单,就是创建一个N*N的二维数组,并为数组的元素初始化赋值。不过如果你没有仔细读代码,可能并不知道两个For循环有什么区别,再好好看看这两句吧。
T1[i][j]=1;
T2[j][i]=1;其实就是赋值的顺序不一样,可以用一张图直观的表示一下。
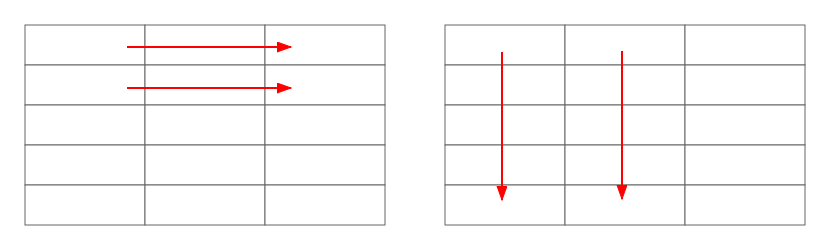
一个是以行优先的赋值方式,另一个是列优先。如果没有学过Cache的相关内容,我肯定不知道这两种赋值方式的执行效率是有区别的。
运行程序之前,先讲原理。我从《计算机组成原理》这本书上摘录了一段话,这段话清楚的讲了CPU是如何从存储器中读到数据的。
《计算机组成原理 第3版》
CPU欲读取主存某字时,有两种可能:一种是所需要的字已在缓存中,即可直接访问Cache;另一种是所需的字不在Cache内,此时需将该字所在的主存整个字块一次调入Cache中。
了解到这个之后,我们还知道,数组其实是占用了一段连续的空间,我们在C语言中,经常通过一些方法移动指针来访问不同的存储单元,也许最常用的方法是这样的。
int a[3]={1,2,3};
int *p=a;
for (int i=0;i<sizeof(a)/sizeof(int);i++)
{
printf("%d\n",*p);
p++;
}既然是一段连续的空间,那Cache在未命中的情况下,访问主存一定是将这一段连续的空间同时读入。我们访问这种连续的存储单元,称为“顺序访问”。很显然,上述程序的第一种赋值方法就是这样做的。
再说另一种赋值方法。我们在以列优先进行访问时,实际上并没有按照存储器中存储的顺序访问。我们在访问完第1行的第1个元素时,其实相邻存储单元存储的是第1行的第2个元素,但我们却选择访问第2行的第1个元素。不过,这个元素仍然有可能在Cache中,但是Cache中用于存储第一行的其余N-1个元素的空间实际上浪费的。在Cache存储空间有限的情况下,这种做法无疑降低了Cache的命中率。我们把这种访问方式称为“跳跃访问”。
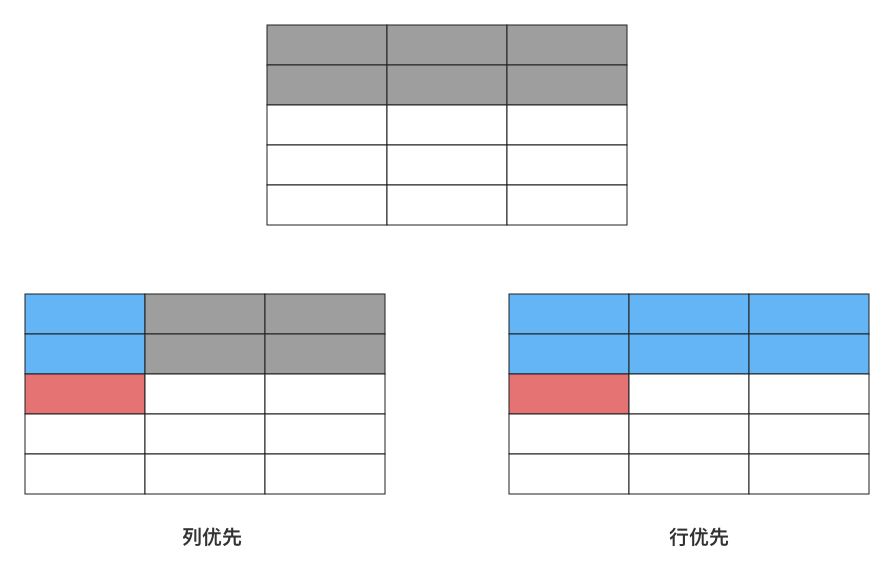
我们下面用一张图直观的描述一下。假设图中灰色的部分是读取数组中已经被读入Cache的部分,蓝色的部分是Cache再次从主存读取数据前,两种方式的命中情况。其实画的不太直观,但我觉得我上面写了这么多,也该理解我想表达的意思了。
注意,不是所有的语言都是按行优先存储数组的,FORTRAN语言是按列存储的,据我了解,其他道还是按行存储的。
最后我们运行一下程序,看看我们的理论到底正不正确。虽然Java并没有直接接触硬件,但这一套原理对JVM肯定也是适用的。
Benchmark Mode Cnt Score Error Units
Cache.Test1 ss 50 641.752 ± 21.236 ms/op
Cache.Test2 ss 50 2014.985 ± 36.929 ms/op差距还是有的,但没有我想的那么大,当然这个跟计算机的硬件也是有关系的。如果想拉开差距,可以尝试着增大N,不过这个运行时间就非常的可观了。我尝试着把N增加到3000,运行结果如下(之前增加到10000的,第1个测试跑了很久,第2个测试直接TimeOut)。
Benchmark Mode Cnt Score Error Units
Cache.Test1 ss 15 5686.538 ± 91.927 ms/op
Cache.Test2 ss 15 71744.410 ± 1835.730 ms/op这个差距就大多了,挺直观的。

写的挺好的,以一个小的例子来展现一部分cache原理,计组我自己上课都没学到太多东西,就记得几个破题的机械做法